[졸업프로젝트] 1: 우리는 오토파일럿을 구현할 수 있을까

요즘은 어쩌면 대학교에서의 마지막 프로젝트가 될지도 모르는 졸업프로젝트에 가장 공을 들이고 있다.
우리가 목표로 하는 것은 ‘AI를 사용한 오토파일럿 구현’으로, 학습시킨 AI 모델이 X-plane 12 환경에서 스스로 안정적으로 비행하는 것이다. 사실 처음에는 수십번의 비행 시물레이션 데이터를 가지고 End-to-End로 학습하면 바로 그럴듯한 모델이 나올 것만 같았다. 간단하고 직관적인 PID 컨트롤러만으로도 원하는 상태를 유지하며 비행하도록 할 수 있기 때문이다.
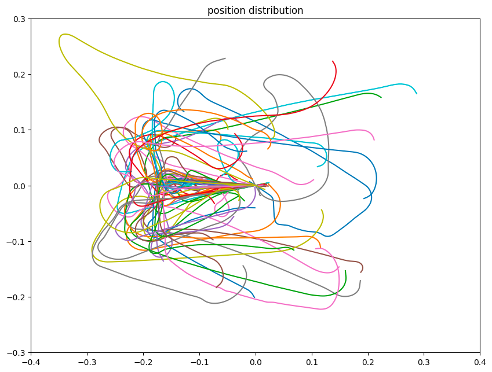
우리가 직접 수집한 데이터도 나쁘지 않은 분포를 가지는 것으로 분석했다. 착륙하는 상황을 가정하고 수집한 데이터라 비행 경로가 임의의 지점에서 시작하지만 같은 활주로에 도달하며 끝나는 것을 볼 수 있다.
모델링은 간단하게, 필요한 것만
베이스라인 모델도 Embodied AI 분야에서 비교적 최근에 제안된 Alfred Benchmark를 가져와 실험했는데, 결과적으로 학습이 거의 되지 않았다. 교수님께서는 vision observation이 다른 Embodied AI 실험 환경에 비해 dominant하게 작용하지 않을 것이라며, vision 부분을 빼는 게 어떻겠냐고 하셨다. 실제로 모델을 단순화하고 input으로 필요한 것만 넣는 게 도움이 되었다. 이제 vision을 생각하지 않아도 되니, sequential information 처리만 잘하면 되는 것이다.
뭔가 될 것 같은 희망감에, 완벽하게 개선된 모델을 만들기 위해 이번엔 PID 컨트롤러의 input/output 형식을 들여다보았다. input으로 현재 step의 state 말고도 state의 오차, state 오차의 누적값을 함께 넣어주었더니 확실히 그럴듯한 결과가 나오기 시작했다.
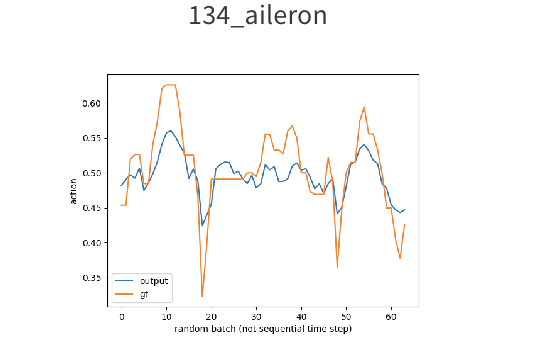
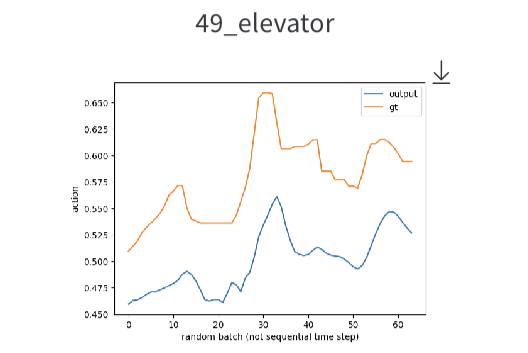
…
그러나 이후에 모델을 어떻게 더 변형해도, 위 그림에서 보이듯 output variable별 학습 결과에 편차가 있었다. 우리는 근본적으로 해결하지 못하는 어떤 문제가 있다고 판단했고, 원인이 되는 요인으로 ‘데이터 부족’을 꼽았다. 그렇다면 어떻게 해야 할까?
Online RL: 학습과 동시에 데이터를 모은다면?
팀원이 RL으로 학습해보는 게 어떻겠냐고 제안했다. 사실 Embodied AI도, 이렇게 긴 시퀀스 데이터 처리도 처음이었는데 강화학습을 또 공부하려니 막막했다. 그래도 해야지 뭐 어쩌겠어.
혹여 독자 중에도 강화학습을 쓰고 싶지만 수학 때문에 엄두가 안나는 분들은, Policy Gradient Algorithms 관련 잘 정리된 블로그 글과 갓-openai의 코드 구현이 포함된 문서를 참고하시면 좋을 것 같다.
아무튼 저 두개로 어찌저찌 자신감은 얻었지만 완벽하게는 모르겠어서, 결과가 좋지 않게 나왔을 때 수정이 어려울 것으로 판단. 최대한 적은 시도로 좋은 결과를 얻고자 자율비행 관련 RL 실험 사례를 많이 살펴보았다. 팀원이 일단 DDPM으로 실험을 돌리는 동안 나는 소형 드론에 대한 RL 실험 사례를 찾았고, 해당 리뷰에서는 DDPM보다는 PPO가 비행에서 더 효율적이며 학습이 잘 된다고 나와있었다. 역시 DDPM 실험 결과는 좋지 않았고, 덕분에 우리는 바로 PPO로 발길을 돌릴 수 있었다.
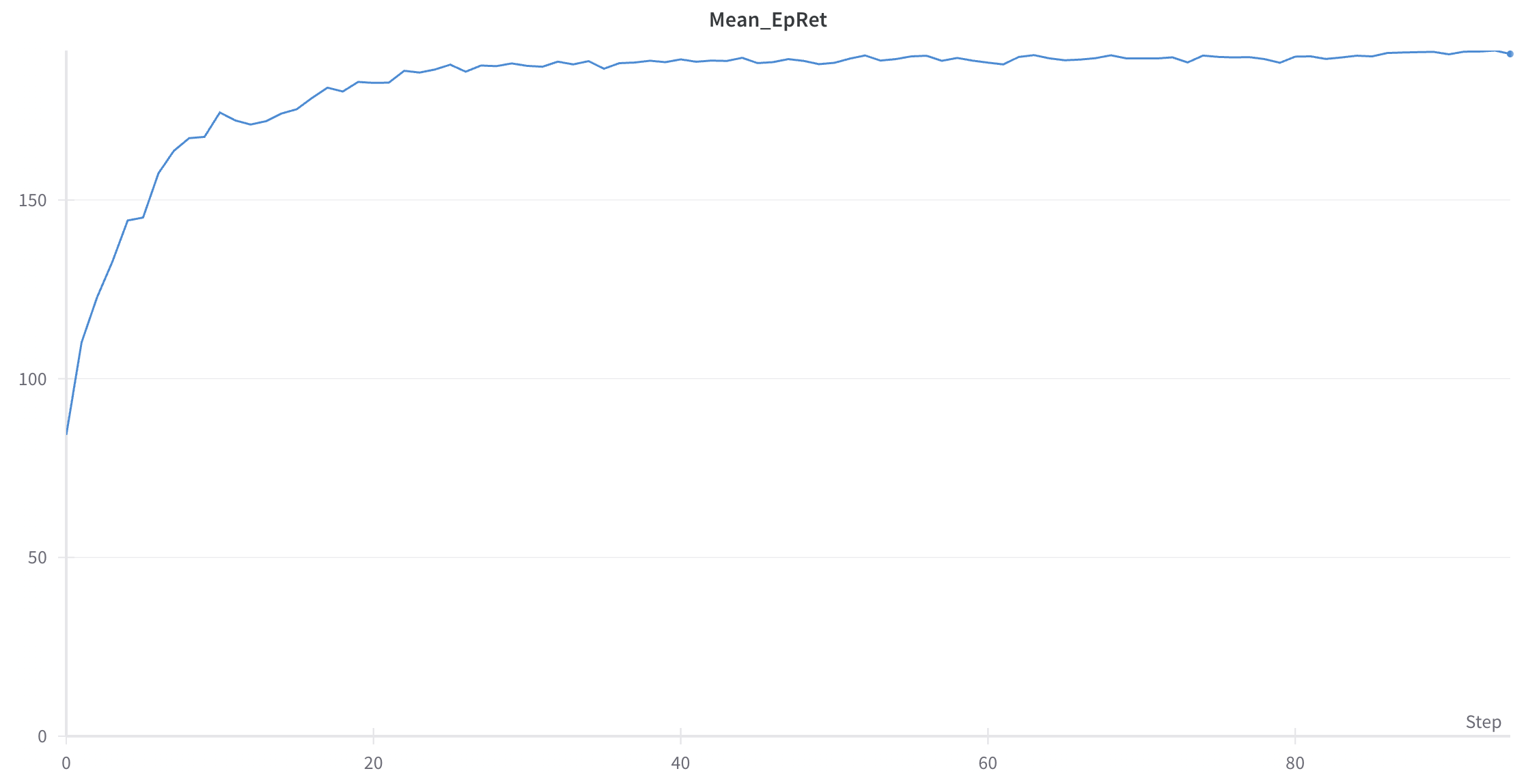
팀원이 reward 함수를 잘 설계한 덕에, PPO로 바꾸자마자 평균 return에서 아주 그럴듯한 곡선이 나왔다. XPlane 시뮬레이션으로도 여태 보지 못했던 성능이 나와, 한동안은 감탄만 했던 것 같다. 아래는 우리의 모델이 각종 괴롭힘에도 불구하고 수평을 잡으며 비행하려는 모습이다.
Reward를 더 효율적으로 설정할 순 없을까
PPO로 학습한 모델이 꽤 좋은 성능을 보여주긴 했지만 reward 함수를 직접 heuristic하게 잡은거라, 최근에는 이것을 어떻게 효율적으로 설정하는 방법이 없을까 연구하고 있다. 아직 실험 결과로 이렇다할 것이 없어서, reward 설정에 관해서는 다음 포스팅에서 다뤄야 할 것 같다.